

When Serverless Meets Traditional Relational Databases
A look into potential issues that may arise when using a Serverless architecture with a traditional Relational Database and potential solutions

FaaS, or Functions as a Service, is a concept you have likely heard of recently as it has rapidly risen in popularity over the past few years.
As more and more people are beginning to take a look at and try out Serverless models in their own projects, be it via AWS Lambda, Azure Functions, or any other provider available, we have began to see the amazing possibilities it brings to the table.
We have also, however, found a few pitfalls. One being the realization that a Serverless model does not get along with a traditional Relational Database very well.
In this article we're going to take a look at some specific problems relating to traditional databases that have been found, and potential solutions to those problems.
What Is Serverless and Why Is It Popular?
Before we dive into the potential issues with Serverless and traditional databases, let's get some insight into what Serverless is and some of the problems it solves.
Shift of Responsibility
A Serverless model, despite its name, still must involve a server. The difference here is a shift in who has to manage that server.
A major selling point of the Serverless architecture is that we as Developers and DevOps Engineers don't have to worry about maintaining the actual server our code is running on. The Serverless provider you use spins up and manages a container for your application to live on automatically.
Potentially Cheaper
Another upside of Serverless is the potential for it to, in the long-run, end up being cheaper than a traditional deployment model.
Your code in this model is no longer running on a server that is charged by the hour or second. Instead, your code becomes available as-needed on a container that is spun up by your provider and brought back down when the request is complete.
Scalability
The last upside is definitely one of the major points of Serverless that makes it a game-changer, and a different class of deployment models.
As mentioned above, your code becomes available as-needed, and as your demand increases your infrastructure will automatically scale up the amount of available instances of your code to support that demand. Individual containers are kept alive for pre-configured amounts of time in case they can be re-used.
This is HUGE as it allows for a significant amount of traffic to be handled in a way that is efficient and cost-effective.
This is also where we find one of the major issues with Serverless in relation to traditional Relational Databases such as MySQL or Postgres.
Where Problems Arise
To better understand why the otherwise beneficial scaling capabilities of Serverless could be a bad thing when paired with traditional databases, let's get an idea of how different deployment models connect to and interact with a database server.
There are many different architectures and models, but we will look at three major ones that tend to be the most commonly seen in the wild:
- Monoliths
- Microservices (Distributed Systems)
- Serverless
Monoliths
In a monolithic architecture, your entire application lives on one server. You might have multiple copies of your entire application on separate servers behind a load-balancer, but the idea is that all of your services, data access layers, user interface, and everything else relating to your application is shipped as one package.
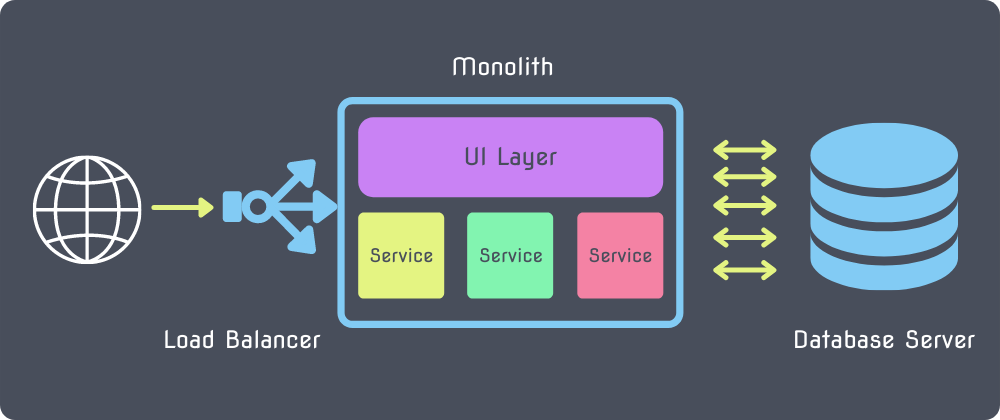
This type of architecture makes it relatively easy to manage connections to a database server. In your application, you can define a connection pool limit and fairly simply and confidently know how many connections to your database to expect from your applications at any given time.
No auto-scaling is going on, no changes are going on. A single set of connections are used for your entire application.
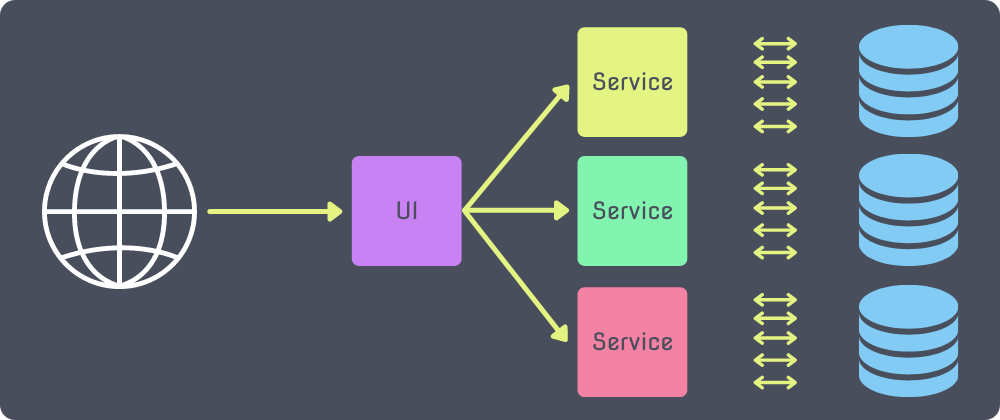
Microservices
In a microservice architecture, things start to get a little bit more complicated. Rather than having one large layer where every piece of your application lives and one database to serve them all, you instead split the application up into logical services. Each service typically has its own set of connections to its own database.
Serverless
Now we get to the topic in question, the serverless model. In a serverless model you can have many different serverless functions running in containers and autoscaling to fit your needs.
These containers are not in existence until called upon via an API gateway, which may trigger a new connection pool to your database server.
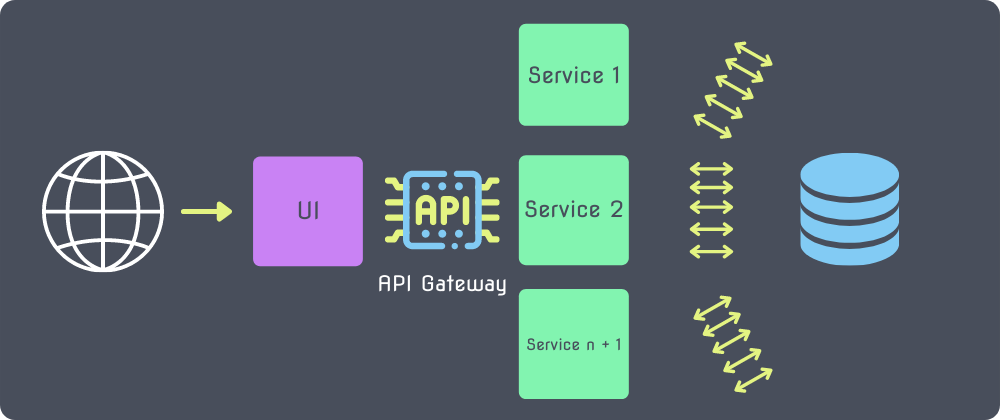
As your application receives more and more traffic, possibly during a peak time, new instances will pop into existence and run concurrently, each setting up a connection pool to the database server. Depending on the traffic this could reach up to 1,000 concurrent executions of your serverless function! (or more)!
Why This Can Be A Problem
As you may have begun to already see, this can pose a real problem for a traditional database.
Any database has a limited amount of connections it will support in order to reserve network and memory usage. In a traditional architecture you would likely have a connection pool set up, which helps manage the re-use of connections and removal of idle or unused connections.
This whole orchestration, however, depends on the concept of keeping a connection open and available. That doesn't really fit into the model of serverless functions that only exist when they are needed. Following this model, you will find that you are frequently and quickly exhausting your connection pool when traffic picks up.
To put this into perspective let's think about some numbers. Let's say we've configured a connection pool in a serverless function with the following settings:
"pool": {
"min": 0,
"max": 15,
"idle": 10000
}
This will tell our function instance that it should open up 15 connections and close out any connections that have been idle for 10 seconds.
| Function Instances | Connections |
| 1 | 15 |
| 5 | ~75 |
| 10 | ~150 |
| 20 | ~300 |
| 50 | ~750 |
Now keeping this in mind, let's take a look at the connection limits for some of AWS's instance classes. The connection_limit for MySQL-Flavored RDS is determined by the calculation: {DBInstanceClassMemory/12582880}.
If we were to choose the db.m5.xlarge instance class which has 16gb of memory, that equates to 1,365 maximum connections. (Keep in mind, we don't want to get close to the limit for performance reasons).
For more info on AWS's connection limits, there is documentation here.
Thinking back on those numbers in the table, imagine your product was having a huge spike in traffic due to an event and 200 concurrent requests hit your API gateway.
At this point, your database would begin to bottleneck. Connections would begin to stack up and soon enough you'd hit the limit.
This could end up being detrimental to the functionality of your code, your data, and even your product's reputation.
While this problem is inevitable with this infrastructure, there are some potential solutions and workarounds that can alleviate, and depending on your needs resolve, the symptoms of this issue.
Potential Code-Based Solutions
The first set of potential solutions are changes and precautions you can implement in your serverless functions to help manage the connection pool a bit.
Lowering The Connection Pool Limit
While keeping a balanced connection pool may be important in a traditional architecture to allow your application to handle concurrent requests to the database, that isn't very import (actually it isn't important at all) in the context of a serverless function.
A serverless function, by design, can only handle a single request at a time. It executes upon receiving a request and traffic to that instance is blocked until the execution resolves.
What this means for us is that we don't really need to care about having multiple connections available to any single instance of our function. We can, and should, set the connection maximum in our pool to 1.
"pool": {
"min": 0,
"max": 1,
"idle": 10000
}
This will significantly boost the amount of concurrent requests your function should be able to handle. As new instances spin up and queues build up on existing instances each new instance will have one open connection to your database server.
Adjusting The Idle Time
While the previous potential solution will likely help out a ton, there are still scenarios where a limit can be hit. Heavy traffic for an extended period of time can cause a myriad of problems.
- More and more instances will be spun up, each opening a database connection
- As instances finish their processes, they will remain open for some time, possibly holding on to their connection
- When a connection is finally dropped from the pool, it does not necessarily mean that connection is available right away. The database engine still needs to process the closing of the connection.
Because of the composition of these problems, connections will continue to rise and rise when receiving massive amounts of rapid requests until the database reaches its max and gets plugged up.
In a short-lived function, lowering the idle time will allow the connections to be dropped from the pool in a shorter amount of time to free up connections for new instances that need a connection.
"pool": {
"min": 0,
"max": 1,
"idle": 5000
}
WARNING: While lowering the idle time can significantly help under extended periods of heavy traffic, lowering it too much can be a negative. In fact, it could significantly hurt your connection availability.
This is because of the fact that a function's execution time may be slower than that idle time if it gets too low. In some edge cases, this may cause a database connection to be dropped from the pool before the function needs it mid-execution, and a new one will need to be created to finish off the request.

The database server likely hasn't closed the connection yet so you are essentially doubling your connections in that instance!
In a long-living function, it may be a good idea to do the opposite and increase the timeout limit to allow you to keep your connections open long enough to be effectively re-used across multiple executions in your instance's lifetime.
Another warning is worth mentioning here. Keeping the connections open for too long may result in an overwhelmed database because more connections may begin to stack up before the cleanup process drops idle connections.
Finding a good balance is key.
A Warning: Manually Closing Connections
One potential workaround worth you might initially think of is manually opening and closing your connections within your actual function to ensure the connection closes at the end of execution.
While this can theoretically lower the amount of concurrent connections, this should not be the go-to solution. You'll likely want to try the other options first and make sure your connection pool settings are optimized.
This is because manually opening a connection on each run creates a trade-off: you get easy connection handling at the cost of huge amounts of latency.
Take this code for example:
module.exports.handler = (event, context, callback) => {
var client = mysql.createConnection({
/* your connection info */
})
client.connect()
/* Your business logic */
client.end()
}
While this would fix the problem of having a stale connection, the latency this would cause by having to open and close a connection on each execution is likely not worth it. There would also be no potential for re-use of connections.
In general, it is recommended to initialize your connection outside of your handler because that connection will get frozen with the instance during downtime and will be thawed if another request in the queue executes the function before it is spun down.
Potential Infrastructure-Based Solutions
Until now we have looked at changes to the actual code that could help lower the amount of concurrent connections. There are also measures we can take on the Infrastructure side to try to streamline some of this.
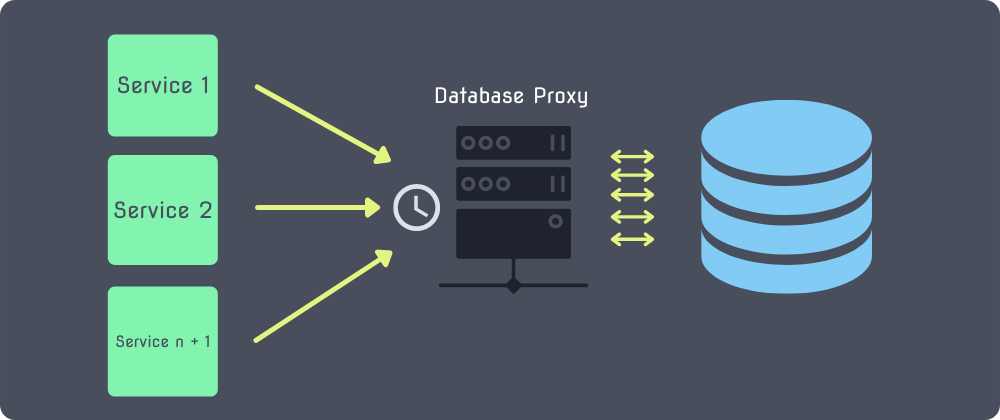
Database Proxy
One possible remedy to the connection pool issue is a Database Proxy such as AWS RDS Proxy or Prisma’s Prisma Data Proxy.
What a database proxy does is manage a connection pool for you outside of your serverless function's context. In doing so, it removes the latency caused by opening a connection for each new instance of your function.
The configured proxy will queue up requests from your functions and throttle them in a way that, although causing some latency, prevents your database from being bombarded with an overwhelming amount of requests at once.
Caching
The last potential solution I will mention is Caching. Effective usage of tools such as AWS's ElastiCache may allow some requests to not have to hit the database at all.
If a set of data is being retrieved from the database often, storing that in the cache will allow you to check for the existence of that data in the cache before running your query. If it exists, you can skip the query altogether!
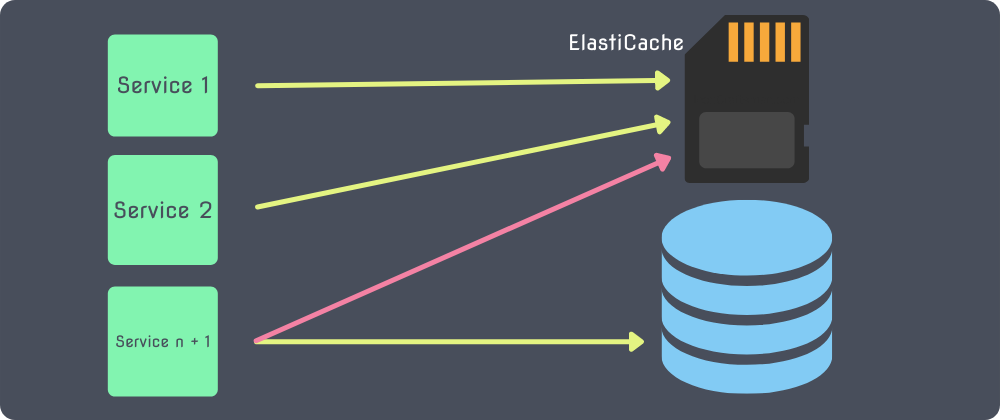
This would cause some, and potentially many, executions of your function that would have otherwise used up a connection to not use one at all! In the long run, under heavy load, this could be HUGE.
Conclusion
In this article we took a look at the potential problems that come about when connecting to a traditional database from a function, or set of functions, deployed using the serverless model.
The solutions, whether used individually or in combination with each other, provide potential resolutions and definite alleviation of the symptoms of this bad relationship between the two technologies.
The main takeaway here should be that a serverless architecture can definitely run effectively in conjunction with a traditional database as long as the proper configurations are put in place and precautions are taken, while taking into consideration how both pieces work individually.
I hope this was helpful in understanding the problem presented and how we might go about avoiding them! Thanks so much for following along!




